| front |1 |2 |3 |4 |5 |6 |7 |8 |9 |10 |11 |12 |13 |14 |15 |16 |17 |18 |19 |20 |21 |22 |23 |24 |25 |26 |27 |28 |29 |30 |31 |32 |33 |34 |35 |36 |37 |38 |39 |40 |41 |42 |43 |44 |45 |review |
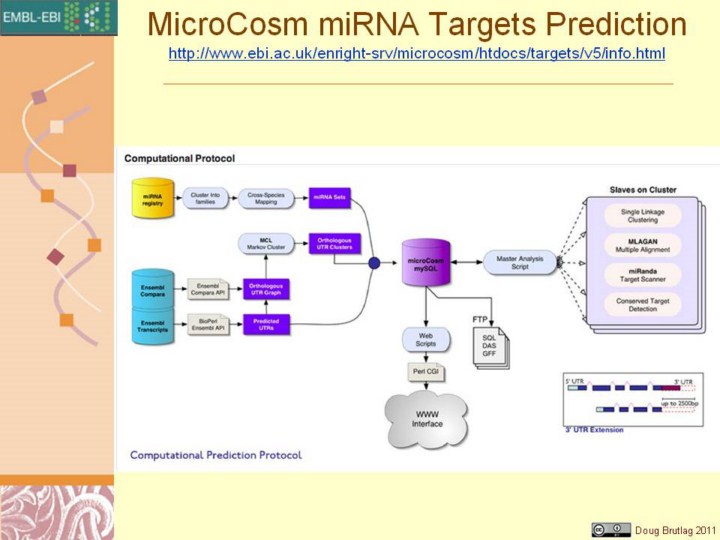 |
http://www.ebi.ac.uk/enright-srv/microcosm/htdocs/targets/v5/info.html MicroCosm is a web resource developed by the Enright Lab at the EMBL-EBI containing computationally predicted targets for microRNAs across many species. The miRNA sequences are obtained from the miRNA Registry and most genomic sequence from EnsEMBL. We aim to provide the most up-to-date and accurate predictions of miRNA targets and hence this resource will be updated regularly.Finding miRNA Target SitesWe currently use the miRanda algorithm to identify potential binding sites for a given miRNA in genomic sequences. The current version uses dynamic programing alignment to identify highly complementary sites which are scored between 0 and 100, where 0 represents no complementarity and 100 complete complementary. The algorithm uses a weighted scoring system and rewards complementarity at the 5' end of the microRNA. Currently we demand strict complementarity at this so-called seed region in accordance with recent publications, this in practice means that we throw away alignments where more than one base in this region is not complementary to a target site. Target sites selected in this fashion are passed through the Vienna RNA folding routines in order to estimate their thermodynamic stability.Finally every potential target site in a 3'UTR detected is checked to see whether the site is conserved in orthologous transcripts from other species. Currently we demand that for a site to be conserved it must be detected at the same position in a cross-species orthologous UTR alignment by an miRNA of the same family. Each target must be conserved in at least two species for inclusion in the database (With the exception of Human and Chimp whose sequences are too similar).The entire process of assembling miRNAs, genomic sequence, cross species UTR alignments and miRanda analysis is performed in parallel on a high-performance compute cluster according to the protocol described below.
|